It is amazing how much you can do on your mobile device without relying on internet connection when using Machine Learning, and I think this is particularly true for image analysis and visional computing.
Yesterday, Frank Doepke, Vision Engineer at Apple, stepped once again on the (virtual) WWDC stage to show the improvements he and his colleagues were up to over the last year. Extract document data using Vision explores the latest updates to barcode detection, text recognition, and document detection.
Here are some highlights from the session:
Barcode detection
VNDetectBarcodesRequestRevision2adds new symbologies and updates the relation of the bounding box which is now relative to the Region of Interest (ROI) and no longer to the whole image (as with Revision 1).
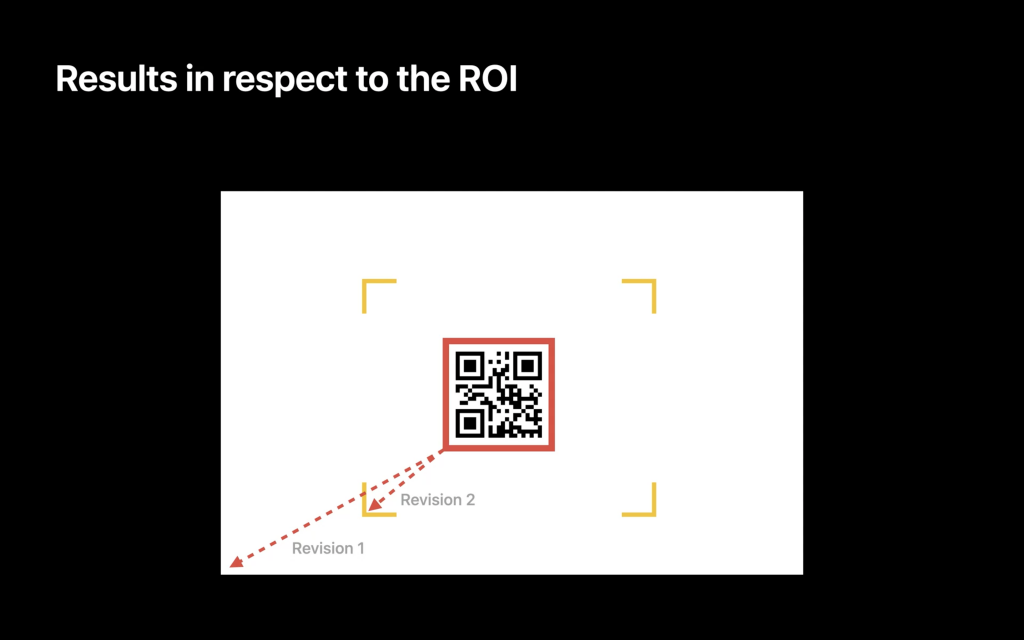
If not specified and compiled against the latest SDK, you will always get the latest revision.- Support for 1D and 2D codes, and the detection of multiple codes and multiple symbologies at once (you can combine both detections) — no need to scan multiple times. However, keep in mind that the detection takes longer if you want to detect multiple codes and/or symbologies. Set up the request only with the codes which are relevant for the respective use case.
- Capabilities to scan codes in low light scenarios
Text recognition
- As a reminder,
VNRecognizedTextRequestcan be used in.fastmode (Latin character recognizer) and.accuratemode (ML-based recognizer) and got a Revision 2 in 2020 - Language selection influences language correction as it picks the correct dictionary
- If multiple languages should be recognized with
recognitionLanguages, keep in mind that the order matters as the recognization gets resolved in the provided order
Document detection
- New ML-based detector
VNDetectDocumentSegmentationRequestwhich was trained on various types of documents (sheets of papers, signs, notes, receipts, labels, etc.) to get a low-resolution segmentation mask — however, this request runs only in realtime on devices with a Neural Engine - Document Segmentation vs Rectangle Detector
